Cleaning Datasets for models Fine-tuning¶
To achieve precise fine-tuning, it's crucial to exercise control over the data, filtering what is relevant and discarding what isn't. Bunka is a valuable tool for accomplishing this task. You can remove cliusters of information automatically and in a few seconds.

| Theme | Google Colab Link |
|---|---|
| Data Cleaning |
Installation via Pip¶
pip install bunkatopics
Installation via Git Clone¶
git clone https://github.com/charlesdedampierre/BunkaTopics.git
cd BunkaTopics
pip install -e .
Quick Start¶
Uploading Sample Data¶
To get started, let's upload a sample of Medium Articles into Bunkatopics:
from datasets import load_dataset
docs = load_dataset("bunkalab/medium-sample-technology")["train"]["title"]
Choose Your Embedding Model¶
Bunkatopics offers seamless integration with Huggingface's extensive collection of embedding models. You can select from a wide range of models, but be mindful of their size. Please refer to the langchain documentation for details on available models.
from bunkatopics import Bunka
from langchain_community.embeddings import HuggingFaceEmbeddings
# Choose your embedding model
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2") # set to True if you have mutliprocessing
# Initialize Bunka with your chosen model
bunka = Bunka(embedding_model=embedding_model)
# Fit Bunka to your text data
bunka.fit(docs)
# Get a list of topics
print(df_topics)
>>> bunka.get_topics(n_clusters=15, name_length=3)# Specify the number of terms to describe each topic
| topic_id | topic_name | size | percent |
|---|---|---|---|
| bt-12 | technology - Tech - Children - student - days | 322 | 10.73 |
| bt-11 | blockchain - Cryptocurrency - sense - Cryptocurrencies - Impact | 283 | 9.43 |
| bt-7 | gadgets - phone - Device - specifications - screen | 258 | 8.6 |
| bt-8 | software - Kubernetes - ETL - REST - Salesforce | 258 | 8.6 |
| bt-1 | hackathon - review - Recap - Predictions - Lessons | 257 | 8.57 |
| bt-4 | Reality - world - cities - future - Lot | 246 | 8.2 |
| bt-14 | Product - Sales - day - dream - routine | 241 | 8.03 |
| bt-0 | Words - Robots - discount - NordVPN - humans | 208 | 6.93 |
| bt-2 | Internet - Overview - security - Work - Development | 202 | 6.73 |
| bt-13 | Course - Difference - Step - science - Point | 192 | 6.4 |
| bt-6 | quantum - Cars - Way - Game - quest | 162 | 5.4 |
| bt-3 | Objects - Strings - app - Programming - Functions | 119 | 3.97 |
| bt-5 | supply - chain - revolution - Risk - community | 119 | 3.97 |
| bt-9 | COVID - printing - Car - work - app | 89 | 2.97 |
| bt-10 | Episode - HD - Secrets - TV | 44 | 1.47 |
Topic Modeling with GenAI Summarization of Topics¶
Explore the power of Generative AI for summarizing topics! We use the 7B-instruct model of Mistral AI from the huggingface hub using the langchain framework.
from langchain.llms import HuggingFaceHub
# Define the repository ID for Mistral-7B-v0.1
repo_id = 'mistralai/Mistral-7B-v0.1'
# Using Mistral AI to Summarize the Topics
llm = HuggingFaceHub(repo_id='mistralai/Mistral-7B-v0.1', huggingfacehub_api_token="HF_TOKEN")
# Obtain clean topic names using Generative Model
bunka.get_clean_topic_name(generative_model=llm)
bunka.visualize_topics( width=800, height=800, colorscale = 'Portland')
Finally, let's visualize again the topics. We can chose from different colorscale.
bunka.visualize_topics(width=800, height=800)
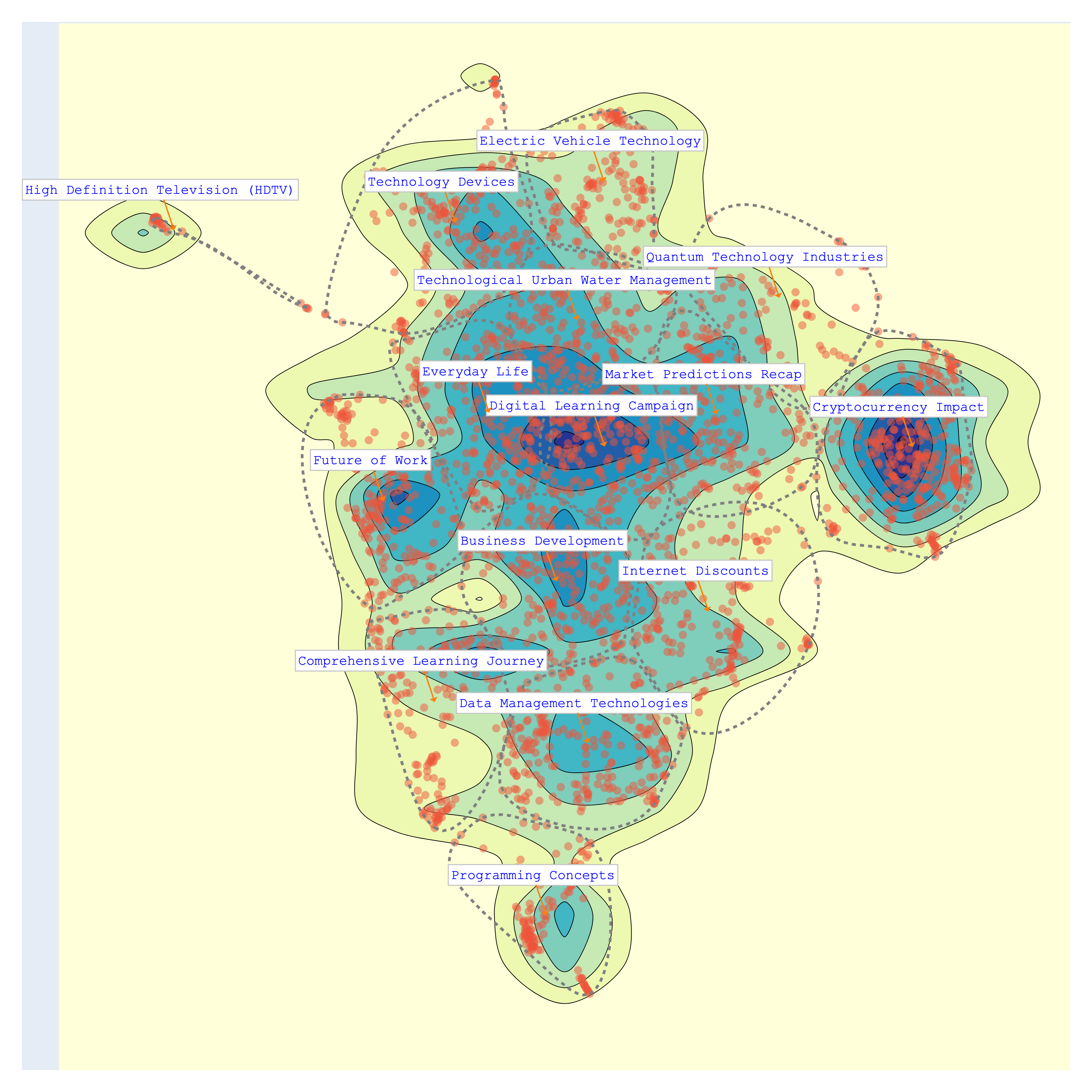
>>> bunka.df_topics_
| topic_id | topic_name | size | percent |
|---|---|---|---|
| bt-1 | Cryptocurrency Impact | 345 | 12.32 |
| bt-3 | Data Management Technologies | 243 | 8.68 |
| bt-14 | Everyday Life | 230 | 8.21 |
| bt-0 | Digital Learning Campaign | 225 | 8.04 |
| bt-12 | Business Development | 223 | 7.96 |
| bt-2 | Technology Devices | 212 | 7.57 |
| bt-10 | Market Predictions Recap | 201 | 7.18 |
| bt-4 | Comprehensive Learning Journey | 187 | 6.68 |
| bt-6 | Future of Work | 185 | 6.61 |
| bt-11 | Internet Discounts | 175 | 6.25 |
| bt-5 | Technological Urban Water Management | 172 | 6.14 |
| bt-9 | Electric Vehicle Technology | 145 | 5.18 |
| bt-8 | Programming Concepts | 116 | 4.14 |
| bt-13 | Quantum Technology Industries | 105 | 3.75 |
| bt-7 | High Definition Television (HDTV) | 36 | 1.29 |
Removing Data based on topics for fine-tuning purposes¶
You have the flexibility to construct a customized dataset by excluding topics that do not align with your interests. For instance, in the provided example, we omitted topics associated with Advertising and High-Definition television, as these clusters primarily contain promotional content that we prefer not to include in our model's training data.
>>> bunka.clean_data_by_topics()

>>> bunka.df_cleaned_
| doc_id | content | topic_id | topic_name |
|---|---|---|---|
| 873ba315 | Invisibilize Data With JavaScript | bt-8 | Programming Concepts |
| 1243d58f | Why End-to-End Testing is Important for Your Team | bt-3 | Data Management Technologies |
| 45fb8166 | This Tiny Wearable Device Uses Your Body Heat... | bt-2 | Technology Devices |
| a122d1d2 | Digital Policy Salon: The Next Frontier | bt-0 | Digital Learning Campaign |
| 1bbcfc1c | Preparing Hardware for Outdoor Creative Technology Installations | bt-5 | Technological Urban Water Management |
| 79580c34 | Angular Or React ? | bt-8 | Programming Concepts |
| af0b08a2 | Ed-Tech Startups Are Cashing in on Parents’ Insecurities | bt-0 | Digital Learning Campaign |
| 2255c350 | Former Google CEO Wants to Create a Government-Funded University to Train A.I. Coders | bt-6 | Future of Work |
| d2bc4b33 | Applying Action & The Importance of Ideas | bt-12 | Business Development |
| 5219675e | Why You Should (not?) Use Signal | bt-2 | Technology Devices |
| ... | ... | ... | ... |